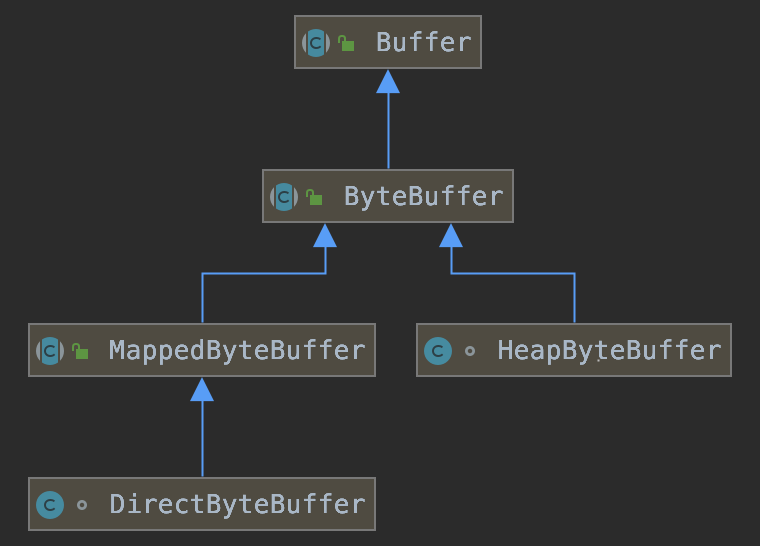
/** * Direct vs. non-direct buffers * A byte buffer is either direct or non-direct. Given a direct byte buffer, the Java * virtual machine will make a best effort to perform native I/O operations directly upon * it. That is, it will attempt to avoid copying the buffer's content to (or from) an * intermediate buffer before (or after) each invocation of one of the underlying * operating system's native I/O operations. * A direct byte buffer may be created by invoking the allocateDirect factory method of * this class. The buffers returned by this method typically have somewhat higher * allocation and deallocation costs than non-direct buffers. The contents of direct * buffers may reside outside of the normal garbage-collected heap, and so their impact * upon the memory footprint of an application might not be obvious. It is therefore * recommended that direct buffers be allocated primarily for large, long-lived buffers * that are subject to the underlying system's native I/O operations. In general it is * best to allocate direct buffers only when they yield a measureable gain in program performance. * A direct byte buffer may also be created by mapping a region of a file directly into * memory. An implementation of the Java platform may optionally support the creation of * direct byte buffers from native code via JNI. If an instance of one of these kinds of * buffers refers to an inaccessible region of memory then an attempt to access that * region will not change the buffer's content and will cause an unspecified exception to * be thrown either at the time of the access or at some later time. * Whether a byte buffer is direct or non-direct may be determined by invoking its * isDirect method. This method is provided so that explicit buffer management can be * done in performance-critical code. **/ publicabstractclassByteBufferextendsBufferimplementsComparable<ByteBuffer> { publicstatic ByteBuffer allocate(int capacity) { if (capacity < 0) thrownewIllegalArgumentException(); returnnewHeapByteBuffer(capacity, capacity); }
# man select select - synchronous I/O multiplexing DESCRIPTION: select() and pselect() allow a program to monitor multiple file de‐ scriptors, waiting until one or more of the file descriptors become "ready" for some class of I/O operation (e.g., input possible). A file descriptor is considered ready if it is possible to perform a corre‐ sponding I/O operation (e.g., read(2), or a sufficiently small write(2)) without blocking.
1 2 3 4 5
# man poll poll - wait for some event on a file descriptor DESCRIPTION poll() performs a similar task to select(2): it waits for one of a set of file descriptors to become ready to perform I/O
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# man epoll epoll - I/O event notification facility DESCRIPTION The epoll API performs a similar task to poll(2): monitoring multiple file descriptors to see if I/O is possible on any of them. The epoll API can be used either as an edge-triggered or a level-triggered interface and scales well to large numbers of watched file descriptors. The central concept of the epoll API is the epoll instance, an in-kernel data structure which, from a user-space perspective, can be considered as a container for two lists: * The interest list (sometimes also called the epoll set): the set of file descriptors that the process has registered an interest in monitoring. * The ready list: the set of file descriptors that are "ready" for I/O. The ready list is a subset of (or, more precisely, a set of references to) the file descriptors in the interest list that is dynamically populated by the kernel as a result of I/O activity on those file descriptors.
The following system calls are provided to create and manage an epoll instance:
* epoll_create(2) creates a new epoll instance and returns a file descriptor referring to that instance. (The more recent epoll_create1(2) extends the functionality of epoll_create(2).)
* Interest in particular file descriptors is then registered via epoll_ctl(2), which adds items to the interest list of the epoll instance.
* epoll_wait(2) waits for I/O events, blocking the calling thread if no events are currently available. (This system call can be thought of as fetching items from the ready list of the epoll instance.)