/** * This class is used to maintain a search path of URLs for loading classes * and resources from both JAR files and directories. * * @author David Connelly */ publicclassURLClassPath { public URL findResource(String name, boolean check) { Loader loader; int[] cache = getLookupCache(name); for (inti=0; (loader = getNextLoader(cache, i)) != null; i++) { URLurl= loader.findResource(name, check); if (url != null) { return url; } } returnnull; }
privatesynchronized Loader getNextLoader(int[] cache, int index) { if (closed) { returnnull; } if (cache != null) { if (index < cache.length) { Loaderloader= loaders.get(cache[index]); if (DEBUG_LOOKUP_CACHE) { System.out.println("HASCACHE: Loading from : " + cache[index] + " = " + loader.getBaseURL()); } return loader; } else { returnnull; // finished iterating over cache[] } } else { return getLoader(index); } }
privatesynchronized Loader getLoader(int index) { if (closed) { returnnull; } // Expand URL search path until the request can be satisfied // or the URL stack is empty. while (loaders.size() < index + 1) { // Pop the next URL from the URL stack URL url; synchronized (urls) { if (urls.empty()) { returnnull; } else { url = urls.pop(); } } // Skip this URL if it already has a Loader. (Loader // may be null in the case where URL has not been opened // but is referenced by a JAR index.) StringurlNoFragString= URLUtil.urlNoFragString(url); if (lmap.containsKey(urlNoFragString)) { continue; } // Otherwise, create a new Loader for the URL. Loader loader; try { loader = getLoader(url); // If the loader defines a local class path then add the // URLs to the list of URLs to be opened. URL[] urls = loader.getClassPath(); if (urls != null) { push(urls); } } catch (IOException e) { // Silently ignore for now... continue; } catch (SecurityException se) { // Always silently ignore. The context, if there is one, that // this URLClassPath was given during construction will never // have permission to access the URL. if (DEBUG) { System.err.println("Failed to access " + url + ", " + se ); } continue; } // Finally, add the Loader to the search path. validateLookupCache(loaders.size(), urlNoFragString); loaders.add(loader); lmap.put(urlNoFragString, loader); } if (DEBUG_LOOKUP_CACHE) { System.out.println("NOCACHE: Loading from : " + index ); } return loaders.get(index); }
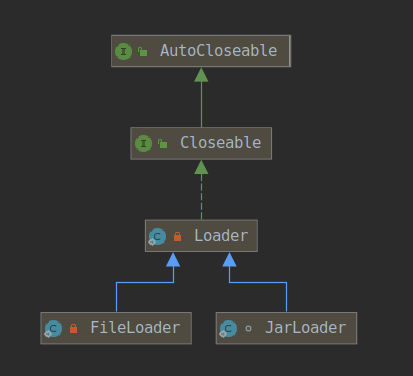
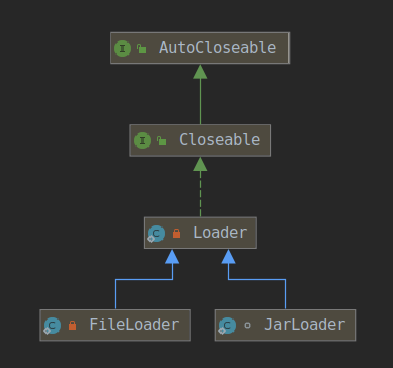
/* * Returns the Loader for the specified base URL. */ private Loader getLoader(final URL url)throws IOException { try { return java.security.AccessController.doPrivileged( newjava.security.PrivilegedExceptionAction<Loader>() { public Loader run()throws IOException { Stringfile= url.getFile(); if (file != null && file.endsWith("/")) { if ("file".equals(url.getProtocol())) { returnnewFileLoader(url); } else { returnnewLoader(url); } } else { returnnewJarLoader(url, jarHandler, lmap, acc); } } }, acc); } catch (java.security.PrivilegedActionException pae) { throw (IOException)pae.getException(); } } }