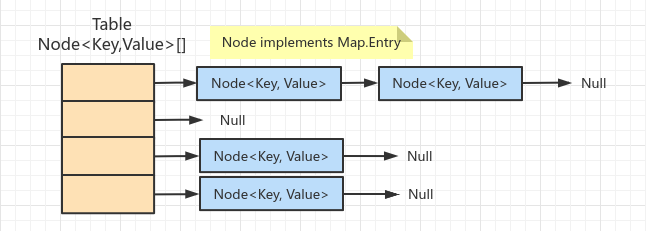
/** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table;
/** * Returns a power of two size for the given target capacity. */ staticfinalinttableSizeFor(int cap) { intn= cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
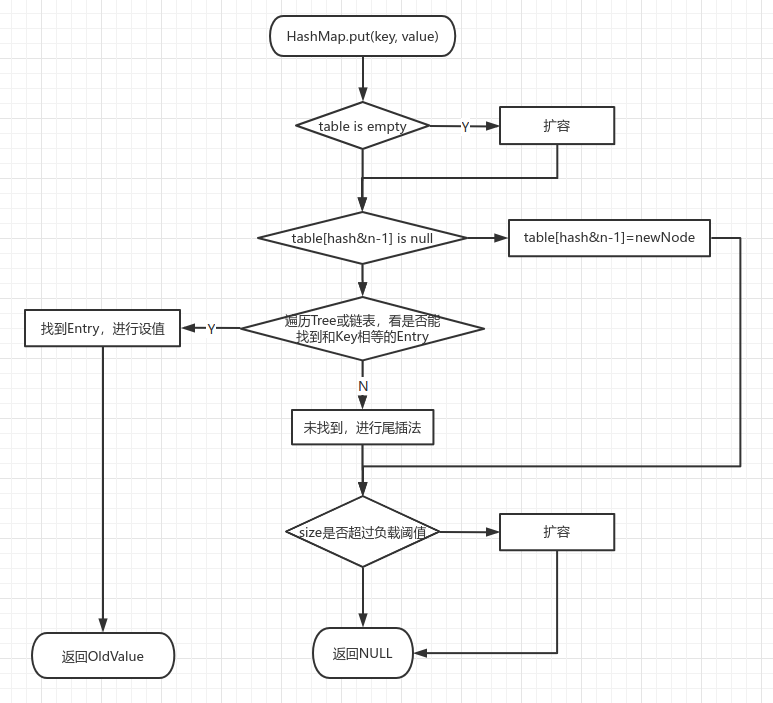
/** * Implements Map.get and related methods. * * @param hash hash for key * @param key the key * @return the node, or null if none */ final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } returnnull; }
/** * Computes key.hashCode() and spreads (XORs) higher bits of hash * to lower. Because the table uses power-of-two masking, sets of * hashes that vary only in bits above the current mask will * always collide. (Among known examples are sets of Float keys * holding consecutive whole numbers in small tables.) So we * apply a transform that spreads the impact of higher bits * downward. There is a tradeoff between speed, utility, and * quality of bit-spreading. Because many common sets of hashes * are already reasonably distributed (so don't benefit from * spreading), and because we use trees to handle large sets of * collisions in bins, we just XOR some shifted bits in the * cheapest possible way to reduce systematic lossage, as well as * to incorporate impact of the highest bits that would otherwise * never be used in index calculations because of table bounds. */ staticfinalinthash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }